KMP
应用场景:字符串匹配及扩展场景
原理
例:字符串"BBC ABCDAB ABCDABCDABDE"是否包含"ABCDABD”

假设已经匹配到当前位置

正常情况下,将目标串右移一位继续进行比较匹配

简单识别后,会发现下一次有意义的比较是将目标串右移4位再进行比较
KMP算法的核心就是如何快速找到下一次有意义的右移,避免无意义的比较,来提高效率
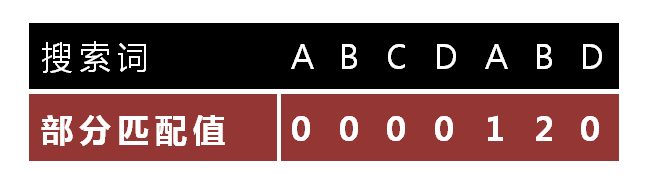
KMP算法,通过构建辅助表(又叫部分匹配表),表中数据表示,当前位置最长“前缀”和“后缀”相同的长度,以前6个字符“ABCDAB”为例
- 相同的最长“前缀”和“后缀”是“AB”,所以第6位是2
- 假设已经匹配到“ABCDAB”前6个字符串,但是第7个字符“D”发现不匹配,这时候前4个字符“ABCD”已经没有比较意义
- 直接将目标串跳过“ABCD”,右移4位继续比较即可
部分匹配表
例:目标串是“ACABACACD”
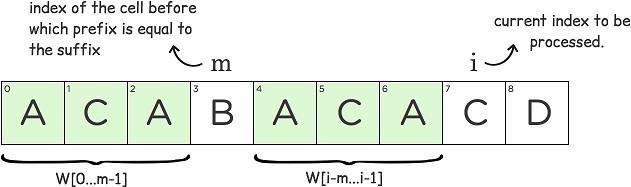
i,表示当前处理的位置 m,表示最长“前缀”和“后缀”的长度
def createPMT(self, w):
aux = [0] * len(w)
i = 1
m = 0
while i < len(w):
if w[i] == w[m]:
m += 1
aux[i] = m
i += 1
elif w[i] != w[m] and m != 0:
m = aux[m-1]
else:
aux[i] = 0
i += 1
return aux
关键点:
- 初始全0,第一个肯定是0,默认从第2个位置开始
- 如果当前位置和最长“前缀”后一个位置相同,表示最长长度又多了一位
- 如果不相同,前面已经有最长“前缀”,则最长“前缀”位置后退一位,继续判断当前位置
- 如果不相同,前面已经没有最长“前缀”,说明当前位置没有最长“前缀”能够匹配到,置0后,继续判断下一位
代码
class KMP:
......
def substring(self, t, w):
aux = self.createPMT(w)
i = 0
j = 0
while j < len(t):
if w[i] != t[j]:
if i == 0:
j += 1
else:
i = aux[i-1]
else:
i += 1
j += 1
if i == len(w):
return j - i
if j == len(t):
return -1
- 匹配没结束,查表后继续匹配
- 匹配结束,匹配到返回首字符位置
- 匹配结束,匹配不到返回-1
参考: