SQL
概述
关系型数据库,主要讨论对表数据查询操作
语法
执行逻辑
从源表数据开始,每个执行逻辑基于前面步骤的源表或虚表生成一个新的虚表,将最后的虚表作为结果返回
执行顺序
SQL实际执行顺序并不是按照语法顺序执行的
- FROM:对子句中表执行笛卡尔积,生成虚表VT1。
- ON:对VT1应用ON筛选器,生成VT2。
- JOIN: 对新表数据按照一定的策略和VT2表中数据进行连接,生成TV3。
- WHERE:对VT3应用WHERE筛选器,生成VT4。
- GROUP BY:按列对VT4中的行进行分组,生成VT5。
- WITH CUTE|ROLLUP:根据聚合策略把聚合数据插入VT5,生成VT6。
- HAVING:对VT6应用HAVING筛选器,生成VT7。
- SELECT:选择SELECT列表,产生VT8。
- DISTINCT:将重复的行从VT8中删除,生成VT9。
- ORDER BY:按列进行顺序,生成一个游标(VC10)。
- LIMIT(TOP):从VC10的开始处选择指定数量或比例的行,生成VT11,并作为结果返回。
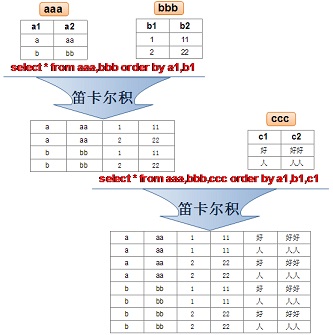
笛卡尔积
A表m行,B表行,C表k行。笛卡尔积ABC=mnk行数据
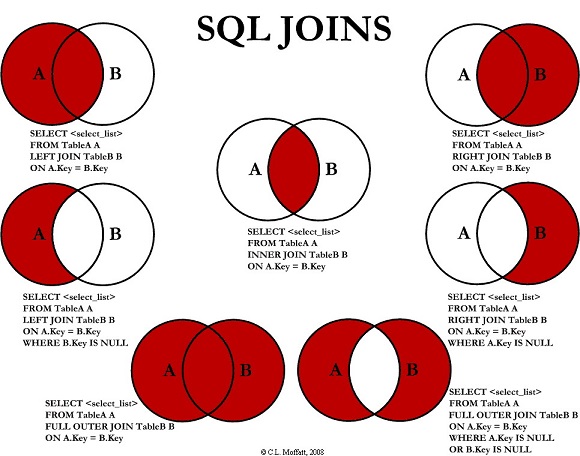
JOIN
先确定基础表,将另外表数据附加到基础表上的过程
表可以SELECT出来的表
默认为INNER JOIN
GROUP BY
如果指定多个列,则按照多个列内容均相同做为分组条件
聚合函数是按组进行聚合执行的
- SUM 计算合计值,该列必须为数值类型
- AVG 计算平均值,该列必须为数值类型
- MAX 计算最大值
- MIN 计算最小值
- COUNT 计数
如果使用了聚合函数但未指定GROUP BY,则默认对整个数据集进行聚合
WITH
- CUTE,对GROUP指定的列进行多维度组合后进行聚合计算,然后插入到虚表中
- ROLLUP,对GROUP指定的最近的列进行单维度聚合执行计算,然后插入到虚表中
HAVING
对GROUP分组后的每组内数据进行条件过滤,通常使用聚合函数作为条件
索引
作用:为数据库中表数据建立数据索引,加速数据访问速度
如果没有建立索引或者数据条件匹配规则不符合索引要求,数据访问需要通过默认的聚集索引进行遍历访问
以Mysql的InnoDB存储引擎为例,索引的存储结构为B+树
聚集索引
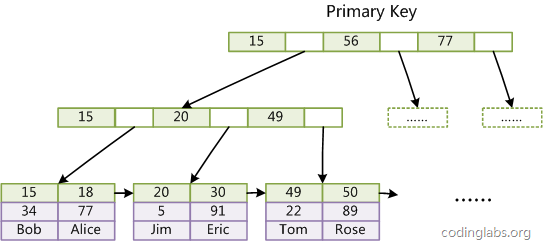
主键索引
InnoDB的数据文件本身就是索引文件,即索引里面直接保存有完整数据记录
辅助索引
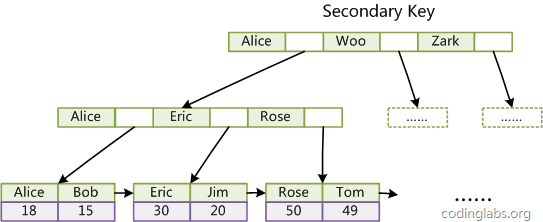
非主键索引
索引里面保存的是聚集索引的数据ID
查找数据需要经过辅助索引和聚集索引2次查找过程
联合索引
对单列索引的扩展,即组合多个列然后进行索引
仍然只有一棵树
符合最左前缀原理
最左前缀原理:即只有和多个列能够有公共的前缀列,才能用到该联合索引,中间不能跳过某些列
Explain
Mysql提供的SQL分析工具
如果不确定编写的SQL执行的情况,可以优先采用Explain进行分析后看是否有优化空间
用法:
mysql> explain select * from servers;
+----+-------------+---------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------+------+---------------+------+---------+------+------+-------+
| 1 | SIMPLE | servers | ALL | NULL | NULL | NULL | NULL | 1 | NULL |
+----+-------------+---------+------+---------------+------+---------+------+------+-------+
1 row in set (0.03 sec)
SQL语句前加上explain关键字即可
说明:
id
- id值越大优先级越高,越先被执行
- id相同时,执行顺序由上至下
select_type
- SIMPLE(简单SELECT,不使用UNION或子查询等)
- PRIMARY(查询中若包含任何复杂的子部分,最外层的select被标记为PRIMARY)
- UNION(UNION中的第二个或后面的SELECT语句)
- DEPENDENT UNION(UNION中的第二个或后面的SELECT语句,取决于外面的查询)
- UNION RESULT(UNION的结果)
- SUBQUERY(子查询中的第一个SELECT)
- DEPENDENT SUBQUERY(子查询中的第一个SELECT,取决于外面的查询)
- DERIVED(派生表的SELECT, FROM子句的子查询)
- UNCACHEABLE SUBQUERY(一个子查询的结果不能被缓存,必须重新评估外链接的第一行)
table
- 用到的数据表
- derivedx(x),派生表,x为第几步
type
- ALL:Full Table Scan, MySQL将遍历全表以找到匹配的行
- index: Full Index Scan,index与ALL区别为index类型只遍历索引树
- range:只检索给定范围的行,使用一个索引来选择行
- ref: 表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
- eq_ref: 类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,就是多表连接中使用primary key或者 unique key作为关联条件
- const、system: 当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量,system是const类型的特例,当查询的表只有一行的情况下,使用system
- NULL: MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成。
possible_keys
可能涉及到的索引
key
实际用到的索引
key_len
- 使用到的索引长度
- 越短越好
ref
哪些列或常量被用于查找索引列上的值
rows
- 大概涉及的行数
- 估算值
Extra
- Using where: 表示仅仅使用了索引中的信息而没有读取实际的行动的表,这发生在对表的全部的请求列都是同一个索引的部分的时候
- Using temporary:表示需要使用临时表来存储结果集,常见于排序和分组查询
- Using filesort:无法利用索引完成的排序操作称为“文件排序”
- Using join buffer:强调了在获取连接条件时没有使用索引,并且需要连接缓冲区来存储中间结果。如果出现了这个值,可能需要添加索引来改进能。
- Impossible where:强调了where语句会导致没有符合条件的行。
- Select tables optimized away:意味着仅通过使用索引,优化器可能仅从聚合函数结果中返回一行
参考: