系统设计入门
概览
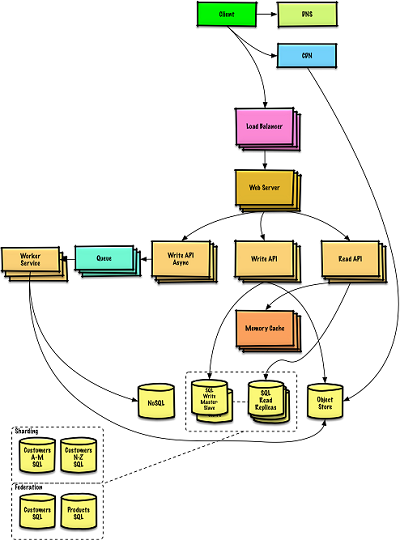
- DNS,第一层路由
- CDN,第二层缓存
- LB,第三层负载
- Web Server和API,前后分离
- Queue,消息队列
- Cache,缓存
- SQL,读写分离
- NoSql,对象存储
DNS
域名结构:
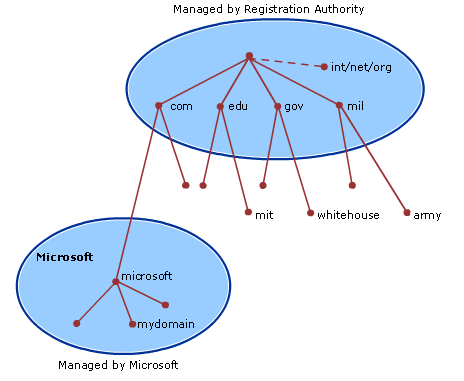
分层管理
域名解析:
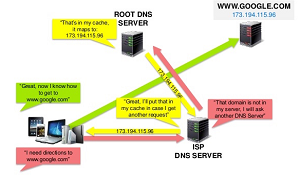
递归:
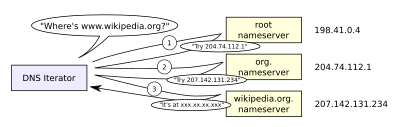
迭代:
资源类型:
- NS 记录(域名服务) ─ 指定解析域名或子域名的DNS服务器。
- MX 记录(邮件交换) ─ 指定接收信息的邮件服务器。
- A 记录(地址) ─ 指定域名对应的IP地址记录。
- CNAME(规范) ─ 一个域名映射到另一个域名或CNAME记录(example.com指向www.example.com)或映射到一个A记录。
优缺点:
- 延迟
- DDOS
- 不可或缺
CDN
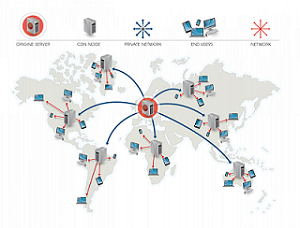
作用:
CDN是一个全球性的代理服务器分布式网络,它从靠近用户的位置提供内容。通常,HTML/CSS/JS,图片和视频等静态内容由CDN提供。
- 从靠近用户的数据中心提供资源
- 通过CDN,服务器不必真的处理请求
内容更新模式:
- 推送(push):服务器上内容发生变动时,推送新内容给CDN,并重写URL地址以指向新内容的CDN地址。流量最小化,但储存最大化。
- 拉取(pull):当第一个用户请求该资源时,从服务器上拉取资源,存活时间(TTL)决定缓存多久时间。最小化储存空间,有冗余流量。适合高流量站点
优缺点:
- 减低服务请求压力
- 流量贵
- 过期,内容更新
LB
LB和Proxy,在大多场景基本是等效的,LB可以运行在Proxy模式,Proxy可以提供LB功能
特性:
主要任务:
位于客户端和服务端之间
- 服务发现,有哪些后端能提供服务,怎么和后端进行通信
- 健康检查,当前哪些后端是好着的能够对外提供服务
- 负载均衡,用什么策略去平衡后端的请求量
主要作用:
- 命名抽象,通过服务发现,提供对后端服务地址的抽象,无序提供具体地址给客户端
- 容错能力,通过健康检查和负载均衡,LB可以跳过坏的或负载高的后端从而实现服务容错
- 成本和性能,LB可以通过流量控制,在区域间合理配置访问流量
OSI
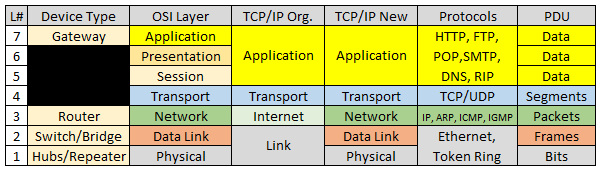
- Layer 7,应用层,人机交互,描述应用怎么收发数据
- Layer 6,表示层,格式化应用层收到的数据
- Layer 5,会话层,保证数据的同步性
- Layer 4,传输层,管理数据包在网络上的传输过程
- Layer 3,网络层,寻址和路由
- Layer 2,链路层,管理数据帧在网卡上的传输过程
- Layer 1,物理层,转换数据帧和电信号
L4
工作在Layer 4层的负载均衡,TCP/UDP connection/session,感知不到应用层数据
TCP/UDP termination load balancers:

- Client和L4建立TCP连接
- L4拦截连接,并选择一个后端,L4和后端建立新的TCP连接
- L4打乱了数据顺序,但是保证同一会话数据在同一的后端上
TCP/UDP passthrough load balancers:
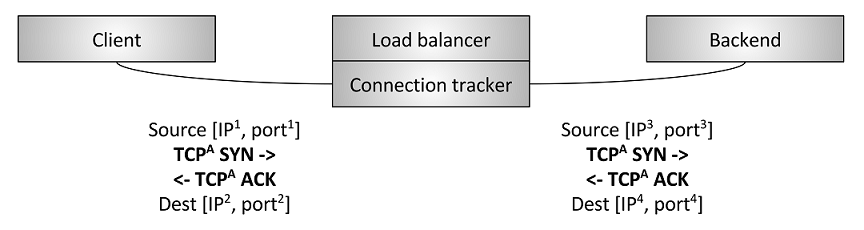
- 通过连接追踪和NAT转换,将客户端连接转发到对应的后端
- 连接追踪:跟踪TCP握手和传输状态
- NAT转换:重写数据包的IP和端口信息
相对Termination型优化:
- 性能和资源使用率,无需缓存TCP连接信息
- 允许后端采用不同的拥塞控制策略
Direct server return (DSR):
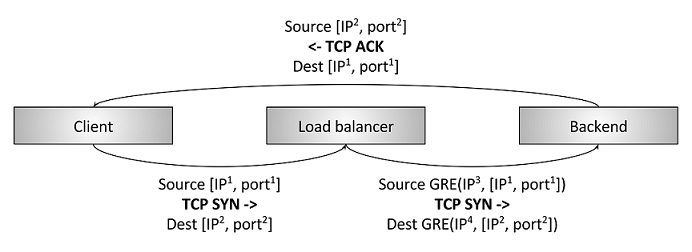
- 进入的流量走passthough模式
- 返回的流程不走LB,直接返回给客户端
适用于少请求内容,大量返回内容的情况
取代NAT,采用GRE封装数据包
L4高可用:
Fault tolerance via high availability pairs:

- HA路由
- 全连接L4
Fault tolerance and scaling via clusters with distributed consistent hashing:

- 全路由
- 全连接L4
- DSR
L4缺点:
场景:
- 两个gRPC/HTTP2客户端
- 第1个请求速率1RPM,第2个请求速率50RPS
- 由于L4保证同一个后端服务同一个session,将导致2个后端负载严重不均衡
更多的出现在multiplexing, kept-alive场景中
L7
工作在Layer 7层的负载均衡
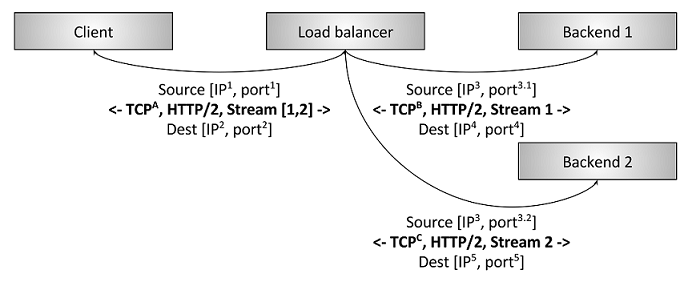
- 客户端和L7建立HTTP/2 TCP连接
- L7中断并和后端建立多个新的连接
特性:
- 多协议支持:HTTP/1, HTTP2, gRPC, Redis, MongoDB, and DynamoDB等
- 动态配置:Istio等
- 功能增强:timeouts, retries, rate limiting, circuit breaking, shadowing, buffering, content based routing等
- 监控:Outputting numeric stats, distributed traces, and customizable logging等
- 扩展:Lua等
- 容错
LB拓扑
Middle proxy:

通用模式
Edge proxy:

Middle的变种,服务对互联网暴露
Embedded client library:
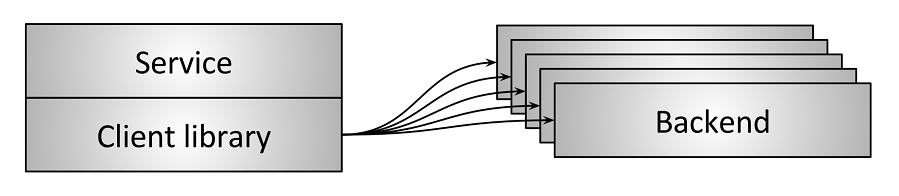
作为lib库,嵌入服务;性能好,但是服务适配困难
Sidecar proxy:
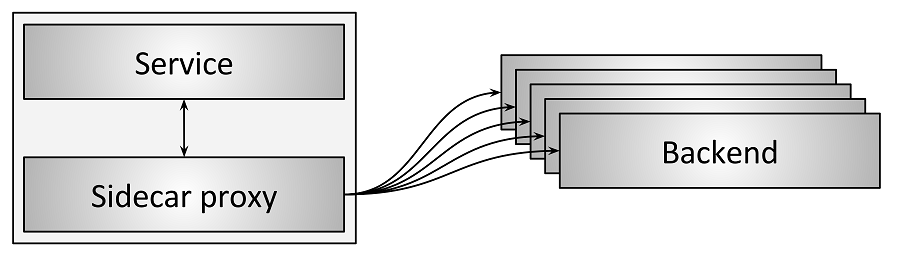
独立代理模式,性能和适配性都不错
Global load balancing and the centralized control plane:
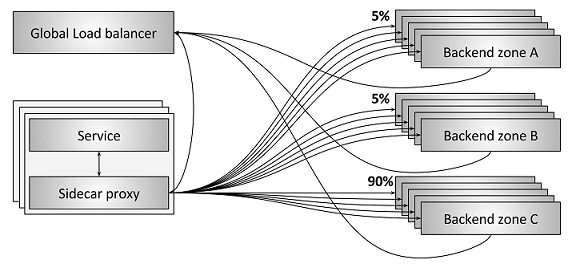
- Sidecar控制流量并上报状态给GLB
- GLB根据实际情况调整Sidecar流控策略
可扩展性
克隆
通常Server都隐藏在负载均衡LB后端,通过对Server的克隆可以提升服务能力的扩展
关键点:
- 每个Server部署的代码完全相同
- 每个Server不在本地或内存保存任何用户状态相关的数据,例如:sessions、配置信息等
- 任何用户状态相关的数据均需要外置保存,例如:database、持久化cache等
数据库
伴随着Server克隆数量的增加,服务的能力对外部Database的依赖越来越严重
关键措施1:
- DBA介入运维
- 设置主从复制,实现读写分离
- 升级服务器规格,增加CPU、内存
- 非规范化操作:sharding、denormalization、SQL tuning
关键措施2:
- 切换NoSQL,例如:MongoDB
- Joins查询,需要从DB转移到应用层
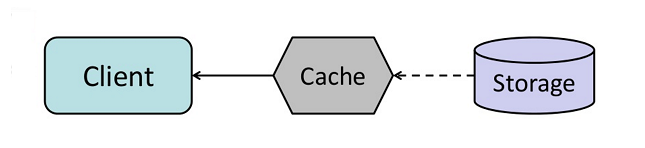
缓存
DB优化后,用户请求大量数据时,依然会存在处理时间较长的情况
关键点:
- 内存Cache,非文件Cache,例如:Memcached、Redis
- 介于应用层和数据层之间,访问数据前,先访问缓存
缓存策略:
缓存Database查询结果:Hash查询语句作为key,存在的问题:容易过期
缓存对象:缓存完整对象(每个部件有不同的库表查询结果组成),方便异步操作(只访问对象即可,不用访问每个部件)
异步
加上缓存后,为异步创建了条件
主动模式:提前处理内容并放入缓存,查询直接查询缓存即可,例如:CMS内容 被动模式:对于计算耗时长的任务,启动后台任务,并进入消息队列,前台启动定时查询任务,待任务完成后通知用户,任务运行期间不影响用户其他操作
缓存
缓存层次:
- 客户端缓存
- CDN 缓存
- Web 服务器缓存:缓存请求
- 数据库缓存
- 应用缓存:数据库查询和对象
更新策略:
缓存模式:
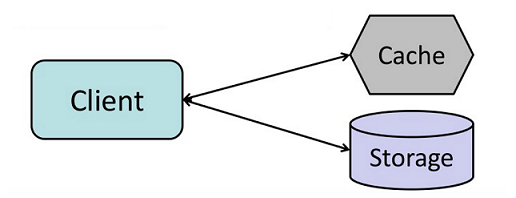
- 访问缓存
- 缓存未中,访问存储
- 保存缓存
缺点:延迟、过期
直写模式:
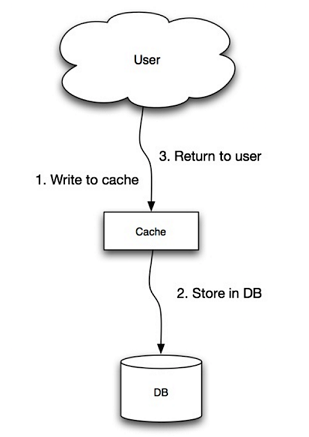
缺点:新增节点,数据缺少缓存
回写模式:
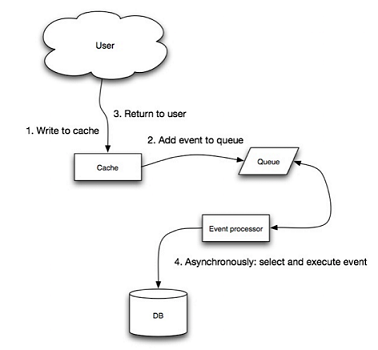
缺点:数据容易丢失
刷新:
自动刷新,适用特定场景:可以准确预测将来可能请求哪些数据
数据库
关系型数据库(RDBMS)
ACID,重点强调一致性
主从复制:
读写分离
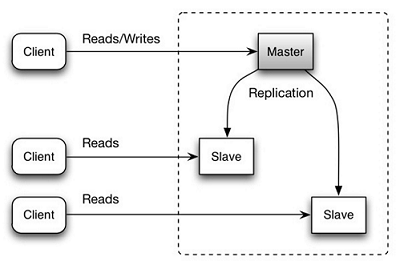
- 需要额外的升主逻辑
- 数据复制问题:丢失、重复、延迟等
主主复制:
双主模式
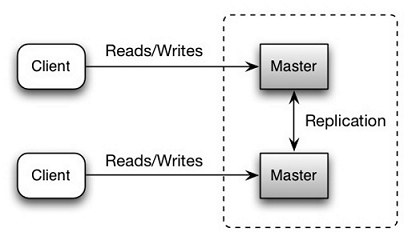
- 需要LB,容易不一致
- 数据复制问题:丢失、重复、延迟等
联合:
分库
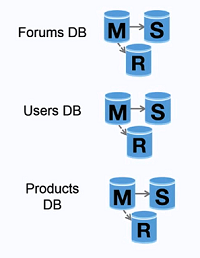
- 联合操作效率不高
- 读写逻辑需要应用层解决
分片:
分表
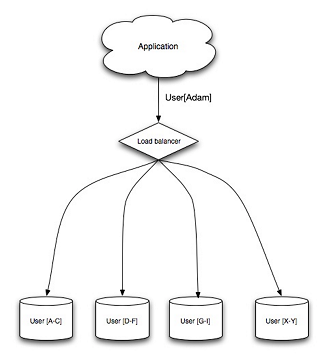
- 读写逻辑复杂,需要应用层解决
- 容易数据负载不均衡
非规范化:
以写入性能为代价来换取读取性能
- 数据冗余
- 设计复杂
- 写入性能不高
SQL调优:
基准测试,性能分析,分析工具
- 类型优化:
- 使用 CHAR 类型存储固定长度的字段,不要用 VARCHAR。
- 使用 TEXT 类型存储大块的文本。
- 使用 INT 类型存储高达 2^32 或 40 亿的较大数字。
- 使用 DECIMAL 类型存储货币可以避免浮点数表示错误。
- 使用 NOT NULL 约束来提高搜索性能。
- 使用正确的索引
- 避免高成本的联合操作
- 分割数据表:将热点数据拆分到单独的数据表中,可以有助于缓存。
非关系型数据库(NoSQL)
BASE,重点强调可用性
- 键-值存储: 哈希表,适用简单数据
- 文档型存储:将文档作为值的键-值存储,具备高度的灵活性,常用于处理偶尔变化的数据。
- 列型存储:嵌套的 ColumnFamily<RowKey, Columns<ColKey, Value, Timestamp» 映射,具备高可用性和高可扩展性。通常被用于大数据相关存储。
- 图存储:图,存储复杂关系的数据模型,如社交网络,提供了很高的性能。
常见应用:
- 埋点数据和日志数据
- 排行榜或者得分数据
- 临时数据,如购物车
- 频繁访问的(“热”)表
- 元数据/查找表
权衡与取舍
性能与可扩展性
- 性能问题:单个用户用起来就比较慢
- 扩展性问题:单个用户没问题,多用户用起来会比较慢
延迟与吞吐量
- 延迟:执行操作或运算结果所花费的时间
- 吞吐量:单位时间内执行操作或运算的次数
应该以可接受的延迟下最大化吞吐量为目标
可用性与一致性
可用性:
- 故障切换:主备切换、主主切换、故障倒换(切换到全新备件)
- 复制:主从复制、主主复制
一致性:
- 弱一致性:写入之后,访问可能看到,也可能看不到(类似掉线)。应用:视频聊天、游戏等
- 强一致性:写入后,访问立即可见(同步复制)。应用:文件系统和关系型数据库等
- 最终一致性:写入后,访问最终能看到写入数据(异步复制)。应用:DNS、email等
CAP
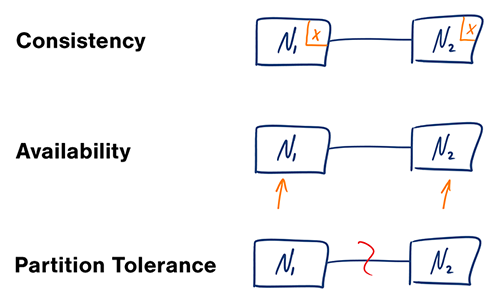
- Consistency - 一致性,每次访问都能获得最新数据但可能会收到错误响应
- Availability - 可用性,每次访问都能收到正确响应,但不保证获取到最新数据
- Partition Tolerance - 分区容错性,在任意分区网络故障的情况下系统仍能继续运行
网络并不可靠,所以要支持分区容错性,但是可用性和一致性无法同时满足,即需要满足AP(适用于原子读写)或CP(适用于最终一致性)
BASE
BASE强调可用性超过一致性, 通常被用于描述NoSQL数据库的特性
- Basically Available - 基本可用,系统保证可用性。例如:响应时间上的损失,功能上的损失等
- Soft State - 软状态,系统状态也可能随着时间变化。例如:副本数据存在中间状态,但不影响系统的整体可用性
- Eventually Consistent - 最终一致性,经过一段时间之后,系统最终会变一致
ACID
ACID追求强一致性模型,传统关系型数据库常用的设计理念
- Atomicity - 原子性,事务中包含的原子操作序列单元,要么全部执行成功,要么全部不执行,任何一项失败,整个事务回滚。
- Consistency - 一致性,事务在执行之前和之后,数据库都必须处于一致性状态。
- Isolation - 隔离性,并发的事务是相互隔离的,一个事务的执行不能被其他事务干扰。
- Durability - 持久性,一个事务一旦提交,对数据库中对应数据的状态变更是永久性的。
参考:
- scalability-availability-stability-patterns
- Understanding Latency versus Throughput
- CAP Theorem: Revisited
- 分布式理论(二) - BASE理论
- 分布式理论系列(一)从 ACID 到 CAP 到 BASE
- From cache to in-memory data grid. Introduction to Hazelcast.
- 可扩展性
- Introduction to modern network load balancing and proxying
- Mastering the OSI & TCP/IP Models
- 系统设计入门
- What is CDN
- DNS Architecture
- Domain Name System
- DNS Security Presentation ISSA